本文共 5085 字,大约阅读时间需要 16 分钟。
一、锁
1.谈谈表锁,行锁,乐观锁
-
锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢)。
1.从对数据操作的粒度分:**表锁**:操作时,会锁住整个表 **行锁**:操作时,会锁定当前操作行
表锁 :开销小,加锁快;不会出现死锁;锁定粒度大,发送锁冲突的概率最高,并发度最低。
行锁:开销大,加锁慢,会出现死锁;锁定的粒度最小,发送锁冲突的概率最低,并发度也最高。
从锁的角度来说:表级锁更适合于查询为主,只有少量按索引条件
2.对数据操作的类型分:
读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响
写锁(排他锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
3.乐观锁:认为自己在使用数据的时候不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。 -乐观锁通过CAS自旋算法实现。
4.悲观锁:认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候先加锁,确保数据不会被别的线程修改。-synchronized关键字和Lock的实现类
5.你平时怎么用synchronized的
二、SpringMVC工作原理以及其重要组件
1.SpringMVC原理
第一步:用户发起请求到前端控制器(DispatcherServlet)第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
第三步:找到以后处理器映射器(HandlerMappering)向前端控制器返回结果-执行链(HandlerExecutionChain)
第四步:前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
第五步:处理器适配器去执行Handler
第六步:Handler执行完给处理器适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView
第八步:前端控制器请求视图解析器(ViewResolver)去进行视图解析
第九步:视图解析器像前端控制器返回View
第十步:前端控制器对视图进行渲染
第十一步:前端控制器向用户响应结果
2.DispatcherServlet的作用
- 中文为前端控制器,提供Spring Web MVC的集中访问点,负责职责的分派,而且与springIOC容器继承。
DispatcherServlet主要用作职责调度工作,本身主要用于控制流程,主要职责如下:
- 文件上传解析,如果请求类型是multipart将通过MultipartResolver进行文件上传解析;
- 通过HandlerMapping,将请求映射到处理器(返回一个HandlerExecutionChain,它包括一个处理器、多个HandlerInterceptor拦截器)
- 通过HandlerAdapter支持多种类型的处理器(HandlerExecutionChain中的处理器)
- 通过ViewResolver解析逻辑视图名到具体视图实现
- 本地化解析以及渲染具体的视图等
- 如果执行过程中遇到异常将交给HandlerExceptionResolver来解析
3.SpringMVC的重要组件
- DispatcherServlet:前端控制器,用于请求到达前端控器,由它调用其他组件处理 用户的请求
- HandlerMapping:处理器映射器,负责根据用户请求找到Handler(处理器),SpringMVC提供不同的映射器实现方式
- Handler:处理器,对具体的用户请求进行处理。
- HandlerAdapter:处理器适配器,通过HandlerAdapter对处理器进行执行
- View Resolver:视图解析器,负责将处理结果生成View视图。View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。
三、Spring
1.让对象与对象(模块与模块)之间的关系没有通过代码来相关联,都是通过配置类来说明管理的(根据这些配置内部通过反射去动态地组装对象)
2.内部最核心的就是IOC了,动态注入,让一个对象的创建不用new了,可以自动的生产,这其实就是利用java里的反射,反射其实就是在运行时动态的去创建、调用对象,Spring就是在运行时,跟xml Spring的配置文件来动态的创建对象,和调用对象里的方法的 。 3.Spring还有一个核心就是AOP这个就是面向切面编程,可以为某一类对象 进行监督和控制(也就是 在调用这类对象的具体方法的前后去调用你指定的 模块)从而达到对一个模块扩充的功能。这些都是通过 配置类达到的。 4.Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明管理的(Spring根据这些配置 内部通过反射去动态的组装对象) 5.要记住:Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
- Bean的生命周期
1.实例化-属性赋值-初始化-销毁
2.实例化和属性赋值对应构造方法和setter方法的注入,初始化和销毁是用户能自定义扩展的两个阶段
具体
1.Spring启动,查找并加载需要被Spring管理的bean,进行bean的实例化。 2.Bean实例化玩后对将Bean的引入和值注入到bean的属性中 3.然后进行实例化的一个应用 4.最后等待销毁四、Mybatis一级缓存和二级缓存以及Mybatis的缓存是怎么实现的?
附:一级缓存和二级缓存的执行顺序(可在mybatis开启日志查看)
1.先判断二级缓存是否开启,如果没有开启,再判断一级缓存是否开启,如果没开启,直接查数据库。 2.如果一级缓存关闭,即使二级缓存开启也没有数据,因为二级缓存的数据从一级缓存获取 3.一般不会关闭一级缓存 4.二级缓存默认不开启 5.如果二级缓存关闭,直接判断一级缓存是否有数据,如果没有就查数据库 6.如果二级缓存开启,先判断二级缓存有没有数据,如果有就直接返回;如果没有,就查询一级缓存,如果有就返回,没有就查询数据库。综上:先查二级缓存,再查一级缓存,再查数据库;即使在一个sqlSession中,也会先查二级缓存;一个namespace中的查询更是如此;
1.Mybaits缓存实现原理()
2.一级缓存和二级缓存
一级缓存
- 一级缓存:SqlSession级别,也叫本地缓存,默认开启,只要在同一个SqlSession中,执行相同的查询语句,并且查到是同一个mapper.xml文件,那么会走一级缓存,SqlSession会话关闭的话,一级缓存就会失效。
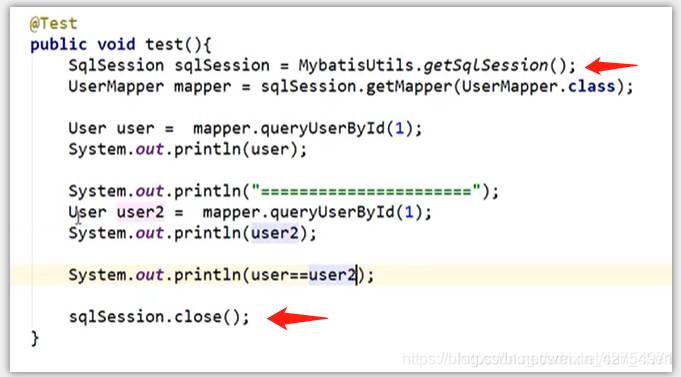 上面的例子中,由于查询的都是id为1的用户,执行的sql语句也是一模一样的,并且是在同一个SqlSession中执行的,那么会走缓存
上面的例子中,由于查询的都是id为1的用户,执行的sql语句也是一模一样的,并且是在同一个SqlSession中执行的,那么会走缓存 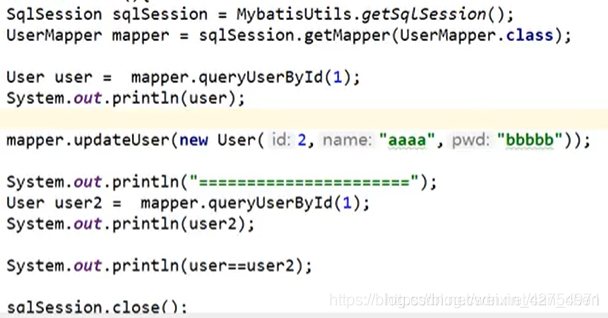 上面的例子中,第二次查询id为1的用户是不走缓存的,因为增删改操作都会导致缓存失效,即使改的数据跟我们查的数据无关
上面的例子中,第二次查询id为1的用户是不走缓存的,因为增删改操作都会导致缓存失效,即使改的数据跟我们查的数据无关
一级缓存失效的情况:
- 查询不同的东西(SQL语句必须一模一样菜会走缓存)
- 增删改操作
- 查询不同的Mapper.xml
- 手动清理缓存(Sqlsession.clearCache())
- SqlSession会话连接关闭
二级缓存(一般不开启,集群的时候会有问题)
- 二级缓存:由于一级缓存作用域太低了,所以诞生了二级缓存,二级缓存是基于**namespace级别的缓存,也就是一个命名空间,**或者叫一个mapper.xml文件,对应一个二级缓存;开启二级缓存只需要在对应的mapper.xml文件中声明一个标签


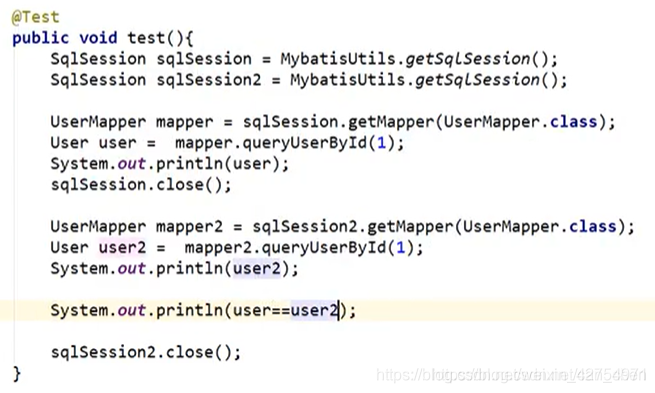 如果是这个执行顺序的话,那么就会走缓存了
如果是这个执行顺序的话,那么就会走缓存了 二级缓存小结: 针对于整个mapper.xml文件,只要开启了二级缓存,在同一个Mapper.xml文件下就能生效;所有的数据都会先放在一级缓存中,只有当会话提交,或者会话关闭的时候,才会提交到二级缓存中
3.实现原理
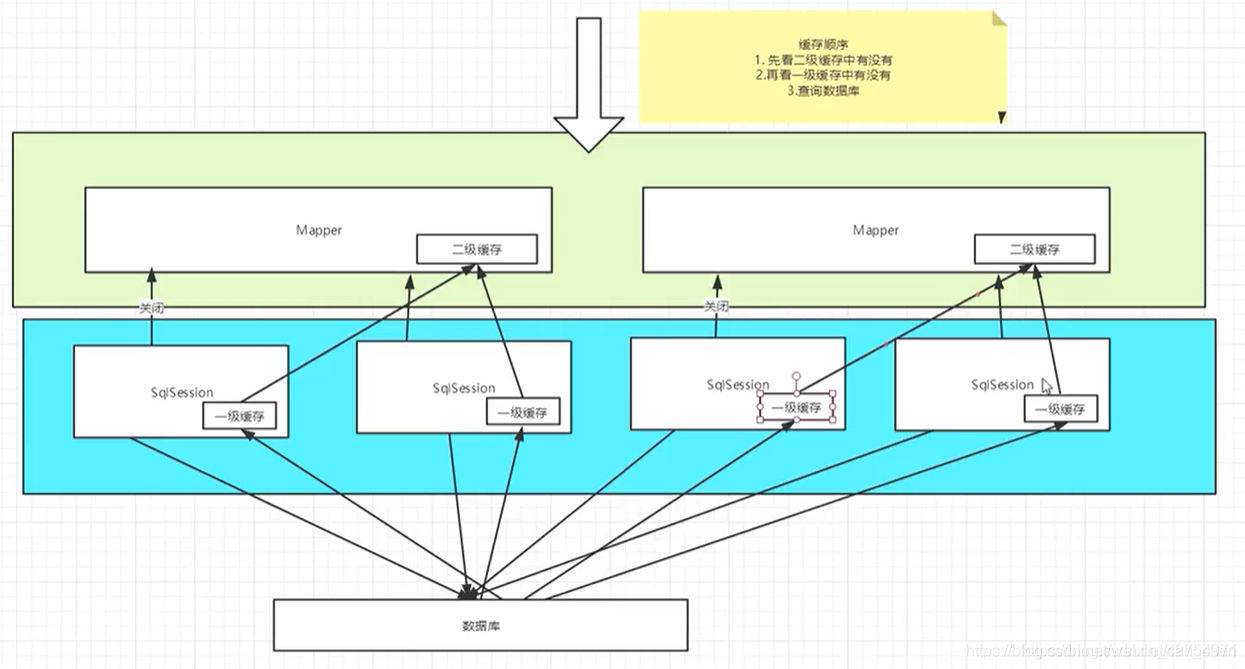 即先去查看二级缓存(namespace级别),如果二级缓存没有的话,再去查看一级缓存,如果没有的话再查数据库;即使在一个sqlSession中,也会先查二级缓存;一个namespace中的查询更是如此;
即先去查看二级缓存(namespace级别),如果二级缓存没有的话,再去查看一级缓存,如果没有的话再查数据库;即使在一个sqlSession中,也会先查二级缓存;一个namespace中的查询更是如此; 五、SpringBoot
1.说说你使用SpringBoot的感受,各种starter是如何实现的,比如我们要整合Mybatis,为什么导入一个starter就可以了
2.SpringBoot常用注解
- @SpringBootApplication
- @Service
- @RestController
- @ResponseBody
- @Component:泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
- @ComponentScan:组件扫描。相当于,如果扫描到有 @Component @Controller @Service等这些注解的类,则把这些类注册为bean。
- @Bean:相当于XML中的,放在方法的上面,而不是类,意思是产生一个bean,并交给spring管理。
- @EnableAutoConfiguration:让 Spring Boot 根据应用所声明的依赖来对 Spring 框架进行自动配置,一般加在主类上。
- @AutoWired:byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。当加上(required=false)时,就算找不到bean也不报错。
- @Qualifier:当有多个同一类型的Bean时,可以用@Qualifier(“name”)来指定。与@Autowired配合使用->
- @Resource(name=“name”,type=“type”):没有括号内内容的话,默认byName。与@Autowired干类似的事。
六、Linux关于查看的命令有哪些
Tail -f看日志
Vi 编辑文档 Ps -ef 查看一些进程,服务有没有跑起来 Netstat 去查看一些端口 Ping 命令看一些网络状态 Find 去查找一些日志的文件 Grep 去进行一些文档内容的搜查七、Lambda表达式
八、线程池的七大参数,执行流程,四种拒绝策略是? 平时选择哪种拒绝策略?
1.重要参数
corePoolSize:核心线程数
queueCapacity:任务队列容量(阻塞队列) maxPoolSize:最大线程数 keepAliveTime:线程空闲时间 rejectedExecutionHandler:任务拒绝处理器(用户可以自定义拒绝后的处理方式)九、MYSQL的三大范式
-1NF即原子性,
-2NF即消除部分依赖 -3NF即消除传递依赖十、索引失效的情况
- 违反最左前缀法则
- 范围查询右边的列索引失效
- 字符串不加单引号
- 对索引列进行运算
- 头部模糊匹配
- 使用不等于! = 或者<>
十一、Spring中用到的设计模式
1.工厂模式:在各种BeanFactory以及ApplicationContext创建中都用到
2.模板模式:在各种BeanFactory以及ApplicationContext实现中也都用到了 3.代理模式:Spring AOP 利用了 AspectJ AOP实现的! AspectJ AOP 的底层用了动态代理 4.策略模式:载资源文件的方式,使用了不同的方法,比如:ClassPathResourece,FileSystemResource,ServletContextResource,UrlResource但他们都有共同的借口Resource;在Aop的实现中,采用了两种不同的方式,JDK动态代理和CGLIB代理 5.单例模式:比如在创建bean的时候。 6.观察者模式 7.适配器模式十二、知道Spring的延迟加载吗?举例应用在什么场景
转载地址:http://cxco.baihongyu.com/